京東智聯云JMR托管集群 釋放海量數據分析潛能的分布式數據計算服務
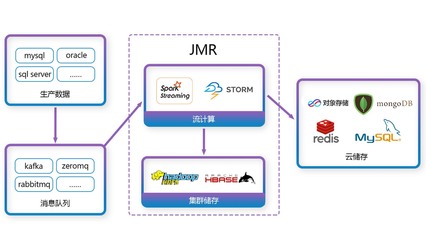
在數據驅動決策的時代,高效、可靠且易用的數據分析和存儲服務已成為企業數字化轉型的核心引擎。京東智聯云推出的JMR(JD MapReduce)托管集群服務,正是為應對海量數據分析挑戰而生的分布式數據計算解決方案。它深度融合了計算與存儲能力,為企業提供了一站式、全托管的大數據處理平臺。
一、 核心價值:托管式服務,聚焦業務本身
JMR托管集群的最大優勢在于其“全托管”特性。傳統的大數據平臺部署與運維往往需要企業投入大量專業人力,涉及集群規劃、環境搭建、組件配置、性能調優、安全管理和日常監控等復雜工作。JMR托管集群則將這些底層基礎設施的繁重運維工作全部接管,用戶無需關心底層服務器的部署、擴縮容、故障恢復與軟件升級。企業數據團隊和開發者得以從繁瑣的集群運維中解脫,將全部精力聚焦于數據本身的價值挖掘和業務邏輯開發,顯著降低了大數據技術的使用門檻和總擁有成本(TCO)。
二、 強大內核:基于成熟生態的分布式數據計算
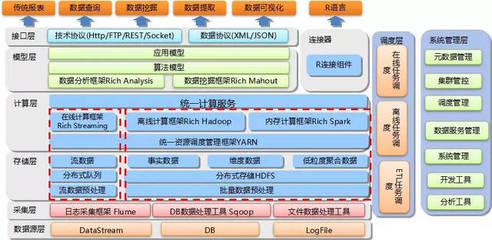
JMR托管集群的核心計算引擎基于業界廣泛采用的Apache Hadoop和Spark開源生態構建,確保了技術的成熟度、穩定性和強大的社區支持。它提供了完整的MapReduce、Spark、Hive、Tez等計算框架,能夠靈活應對批處理、交互式查詢、流處理(結合相關組件)等多種計算場景。
- 海量數據分析能力:依托分布式計算架構,JMR可以輕松處理PB乃至EB級別的海量數據。通過將計算任務分解并分發到成百上千個節點上并行執行,它實現了對超大規模數據集的高效分析,將以往需要數小時甚至數天的分析任務縮短到分鐘級別。
- 彈性伸縮與高性能:集群支持根據計算負載進行彈性伸縮。在業務高峰或處理大型作業時,可快速擴展計算資源以加速任務完成;在閑時則自動收縮,優化成本。結合京東智聯云的高性能云硬盤和對象存儲,實現了計算與存儲的高效協同,保障了整體數據處理管線的吞吐性能。
三、 無縫集成:統一的數據分析與存儲服務
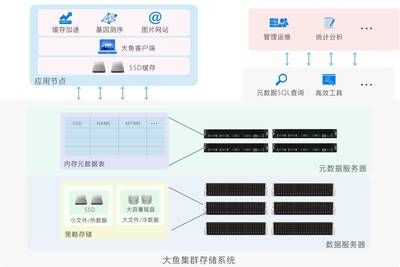
京東智聯云為JMR托管集群提供了深度整合的數據存儲底座,特別是與對象存儲服務的高效對接。用戶可以將海量的原始數據、中間結果和最終報表存儲在可靠、低成本、無限擴展的云存儲中,JMR集群直接對這些存儲中的數據進行計算,實現了“存算分離”的先進架構。
這種架構帶來了多重好處:
- 成本最優:存儲與計算資源獨立伸縮,避免為存儲而預留計算資源造成的浪費。
- 數據持久與共享:數據獨立于計算集群生命周期存在,安全持久,并可被多個不同計算集群(如JMR、數據倉庫、AI平臺)共享分析,打破數據孤島。
- 運維簡化:計算集群的維護、升級或重建不再影響核心數據資產的安全與可用性。
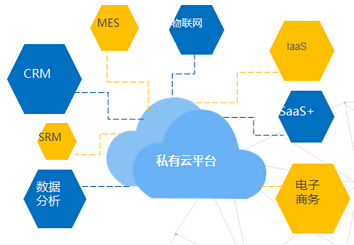
四、 應用場景:賦能多行業數據智能
JMR托管集群服務適用于各類需要對海量數據進行深度挖掘的場景:
- 互聯網與電商:用戶行為日志分析、個性化推薦、廣告效果評估、交易風險監控。
- 金融科技:信貸風控建模、反欺詐分析、交易流水審計、合規報告生成。
- 物聯網與智能制造:設備傳感器數據實時/離線分析、預測性維護、生產流程優化。
- 科學研究:基因組學數據分析、天文觀測數據處理、氣候模擬運算。
###
京東智聯云JMR托管集群作為一款企業級的分布式數據計算服務,通過全托管的云服務模式,將復雜的大數據技術棧轉化為即開即用、彈性高效的分析能力。它與云存儲服務的無縫集成,構成了完整的數據分析與存儲解決方案,使企業能夠以更低的成本和更高的敏捷性,從容應對海量數據帶來的挑戰,快速將數據資源轉化為切實的業務洞察與競爭力。對于尋求快速構建大數據分析能力、又不希望陷入復雜運維泥潭的企業而言,JMR托管集群無疑是一個理想的選擇。
如若轉載,請注明出處:http://www.xyfgd.cn/product/57.html
更新時間:2026-05-24 19:16:03